O projeto
O Olist Dashboard é uma análise interativa de ~100 mil pedidos reais do marketplace Olist, cobrindo o período de 2016 a 2018 no Brasil. O objetivo: transformar dados brutos em insights acionáveis usando Python, Pandas e Machine Learning.
Acesse em: olist.catiteo.com
O dataset é público no Kaggle (licença CC BY-NC-SA 4.0) e contém 9 tabelas relacionais com pedidos, clientes, produtos, vendedores e avaliações — um dos datasets mais ricos de e-commerce brasileiro disponíveis.
As 5 análises do dashboard
1. KPIs Gerais
Painel executivo com os números que mais importam: receita total, quantidade de pedidos, ticket médio, nota média de avaliação, prazo médio de entrega e métodos de pagamento preferidos.
2. Mapa Geográfico
Um choropleth interativo do Brasil mostrando a distribuição de receita por estado. Imediatamente visível: SP, RJ e MG concentram a maior parte do volume, mas estados do Sul têm ticket médio mais alto.
import plotly.express as px
fig = px.choropleth(
df_states,
geojson=brazil_geojson,
locations="state_code",
color="revenue",
color_continuous_scale="Viridis",
title="Receita por Estado"
)
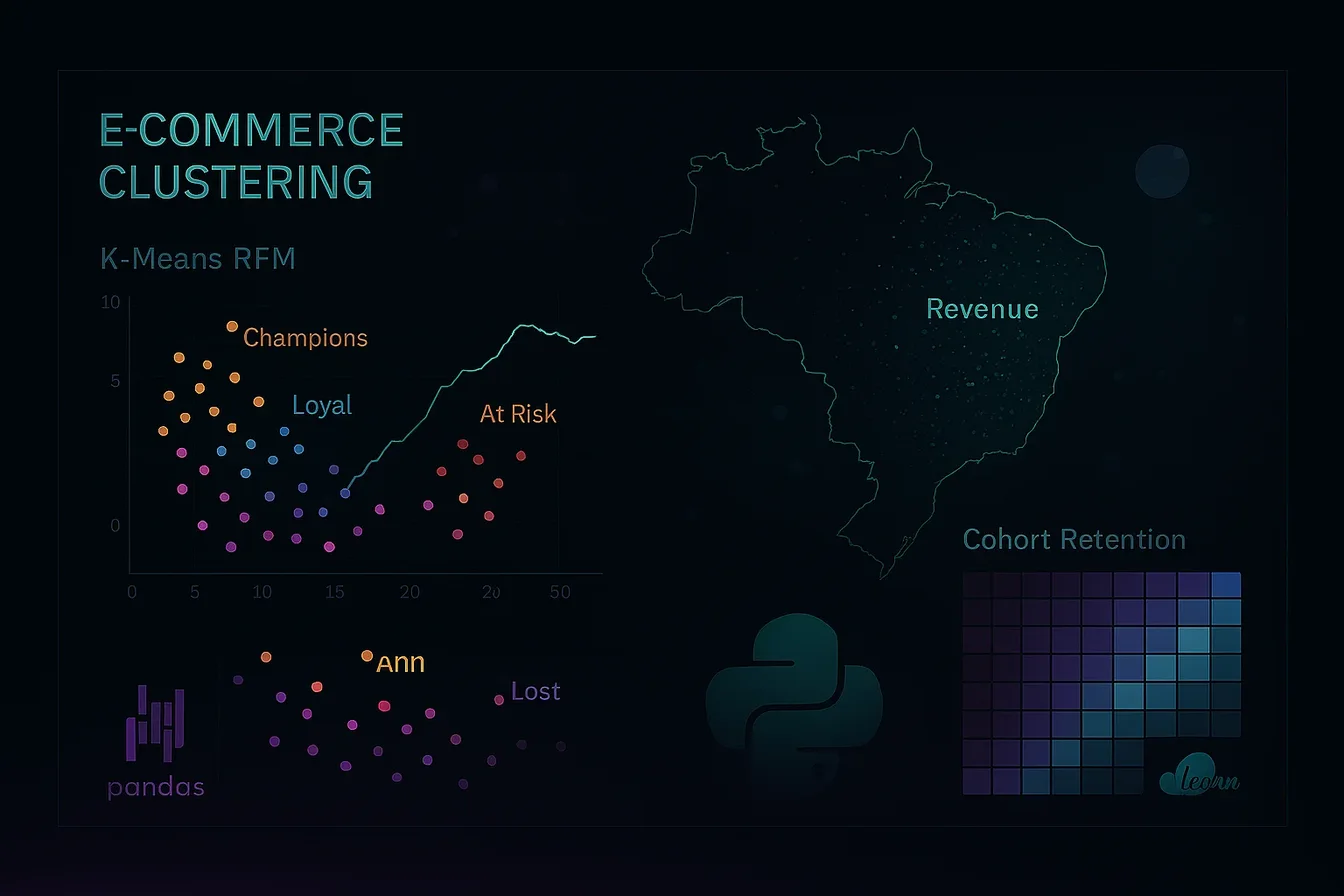
Essa é a parte mais interessante do projeto. A análise RFM (Recência, Frequência, Valor Monetário) classifica cada cliente em um dos 4 perfis usando K-Means com k=4:
| Segmento |
Característica |
| Champions |
Compraram recentemente, com frequência e gastam muito |
| Loyal |
Compram com frequência e bom valor |
| At Risk |
Eram bons clientes mas sumiram |
| Lost |
Compraram uma vez, há muito tempo, pouco valor |
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
rfm = df.groupby("customer_id").agg({
"order_purchase_timestamp": lambda x: (reference_date - x.max()).days,
"order_id": "count",
"payment_value": "sum"
})
scaler = StandardScaler()
rfm_scaled = scaler.fit_transform(rfm)
kmeans = KMeans(n_clusters=4, random_state=42)
rfm["cluster"] = kmeans.fit_predict(rfm_scaled)
O resultado revelou que apenas 8% dos clientes são Champions, enquanto 47% são Lost — compraram uma vez e nunca mais voltaram. Isso explica por que o Olist investiu pesado em retenção pós-2018.
4. Análise de Cohort
Heatmap de retenção mensal mostrando qual porcentagem de clientes de cada mês volta a comprar nos meses seguintes. A conclusão: taxa de retenção média de apenas 3% — típico de marketplace generalista no Brasil.
5. Categorias e Entrega
Top 15 categorias por receita e um scatter plot mostrando a relação entre prazo de entrega e nota de avaliação. Resultado: cada dia a mais na entrega reduz a nota em ~0,15 ponto.
Arquitetura: Python gerando HTML estático
O projeto usa uma abordagem inusitada — não há servidor web nem Streamlit rodando. Um script Python processa os dados e usa Jinja2 para gerar um único index.html com todos os gráficos Plotly embutidos.
python download_dataset.py # Baixa os CSVs do Kaggle
python build.py # Processa e gera output/index.html
O arquivo final é hospedado no Cloudflare Pages como HTML estático. Sem backend, sem custo.
Stack técnica
Linguagem: Python 3.12
Dados: Pandas 2.x + NumPy
Visualização: Plotly (gráficos interativos embutidos no HTML)
ML: scikit-learn (K-Means para segmentação RFM)
Templating: Jinja2
Dataset: Olist / Kaggle (~100k pedidos, 9 tabelas)
Deploy: Cloudflare Pages (HTML estático)
O que aprendi
Segmentação RFM é simples e poderosa. Três métricas, um algoritmo de clustering, e você tem uma visão clara de quem são seus melhores e piores clientes. É uma das análises mais práticas do arsenal de data science.
Dados reais são bagunçados. O dataset do Olist tem pedidos cancelados no meio, endereços inconsistentes e timestamps fora de ordem. Boa parte do trabalho foi limpeza e validação antes de qualquer análise.
Gerar HTML estático é subestimado. Para dashboards que não precisam de dados em tempo real, gerar um index.html com Plotly embutido é a solução mais simples, performática e barata possível.
Código e demo
Código no GitHub e demo ao vivo em olist.catiteo.com.